Last year I wrote this post about the new composite model feature in Power BI that enables datasets to be chained together using a featured called “DirectQuery for PBI Datasets and AS“. The prospect of creating a data model that virtually layers existing data models together without having to repeat the design, sounds like nothing less than Utopia. We can leverage existing datasets, with no duplicate models, no duplication of business logic, and no duplication of effort. The promise of this capability is that data models may be referenced from other data models without duplicating data. So, is this really possible?
The feature we are discussing in this post is not for beginners and it is in Preview, with some important limitations that should be considered in the overall solution architecture. Make sure you understand these trade-offs before using this feature.
When the new composite model feature (using DirectQuery for AS) was released to Preview last year, I gave it a thorough test as did others in the community. It was cool and I was able to whip up a few demos, but right from the gate, I could see that it wasn’t ready for production use. The product engineering teams have been working on this dream feature for years, and there are several dependencies in the Power BI service (Gen2 architecture), the VertiPaq engine, and the Power BI Desktop model designer that needed to be orchestrated. It is complex and will be slow to mature.
The most significant shortcomings, in my opinion, were that in the local model (where you add DirectQuery connections to existing, published data models), you couldn’t add objects with duplicate names. If any measures with the same name exist in the remote data model, you couldn’t add a reference to the remote model. If you could get past resolving the measure name conflicts, when connecting to a remote data model, you get every single table in the remote model; thus, compounding the duplicate object name issue. Cool technology with lots of promise but there were significant implementation blockers from the get go.
The product teams were notably quiet over the past year, with very little news about enhancements to this feature. With all the fanfare about the Preview launch last year, I was looking for more news about critical feature updates. There have been a lot of organization changes and feature reassignments at Microsoft this year, so maybe the work on this feature just hasn’t been visible externally. But alas, there is good news! As of the October Desktop update, the composite model design experience has improved significantly. Any duplicate measure names are now resolved by the designer by adding numbers to the end. You can now select only the tables you want to bring into the local model after connecting to a remote model.
New Concepts and Terminology
Gen2 composite models introduce some new concepts and terms that are important to understand. Before you can grasp these new composite model concepts, you must understand the fundamental data modeling architecture in the SSAS Tabular/VertiPaq modeling engine, which is utilized within Power BI.
Direct Connect and DirectQuery
The first thing is that when you create a new report connected to a published Power BI dataset, this uses “Live Connect” which is the default mode for Power BI reports connected to a published dataset. To enable a Gen2 composite model, this connection must be changed to use DirectQuery, using the XMLA endpoint, to connect to the remote published data model as an Analysis Services connection.
Chaining
A data model that references another data model is referred to as a chain of models. Currently, up to three levels of chaining are supported. This means that if you have a data model that imports or connects to data sources, that published dataset can be referenced by another data model. The second model can then be published as a dataset. The latter dataset may reference multiple published datasets but it cannot be used as a DirectQuery source for a third data model. The product documentation uses the following illustration to demonstrate the limits of a three-level chain. In this example, the Sales data model is an Azure Analysis Services data model referenced as a remote dataset by the Sales and Budget dataset.
Note: The Sales AAS model in this example could just as well be a published Power BI dataset because the XMLA endpoint sees them as the same type of SSAS Tabular model connection.
The Sales and Budget dataset, in turn, is referenced as a remote dataset by the Sales and Budget Europe dataset. As illustrated by the Budget Excel source, any of these data models can have a variety of connectors used to import or connect to various data sources.

You can create relationships between the tables from different sources as long as they don’t violate the rules for existing relationships, either in the local data model or relationships that exist in the underlying remote data model. Since the local model developer may not have visibility to the entire schema for the remote model, this is a complexity to consider when using composite models. This is an example of why composite models are not for beginners.
Remote data model
From the perspective of the “local” data model that is open in the Desktop designer, when a published dataset is referenced by another data model, it is referred to as a Remote dataset.
Local data model
Any published dataset (within the limits of this feature) can be used in a remote connection. The data model that connects to a remote dataset is referred to as the Local dataset.
Relationships may be created between tables from different remote datasets. These relationships should generally behave like they do in standard data models but there are some limits and subtle behavioral differences. There are still features of Power BI and Azure Analysis Services features that are unsupported in Gen2 composite models, so use this with caution and consult the documentation for details: Using DirectQuery for datasets and Azure Analysis Services (preview) – Power BI | Microsoft Docs.
Remote table relationships
What are those funny icons on the relationship lines between local and remote tables? These denote that the relationship is “limited”, otherwise known as a “weak” relationship. This means, in simple terms, that since the relationship is defined using columns from tables in different DirectQuery sources, the VertiPaq engine cannot guarantee that the usual cardinality and key uniqueness rules can be enforced. These rules are inferred by the modelling engine but could potentially be violated and produce inconsistent results. By defining a relationship, as the model author, you are essentially stating that you expect the data to conform to cardinality and key-matching rules without the ability to force the model to behave that way. Alberto Ferrari wrote an extensive article explaining these relationship types in detail.

New Composite Model Features
I’m not going to walk through an entire demo because this would repeat the same steps as my previous post from December 2020, but I will get started (again). If you are interested in stepping through the process, I suggest following the instructions in that post. There are a few significant improvements from the previous design experience:
- Duplicate measure names are automatically resolved
- Individual tables can be selected when adding a new remote dataset connection
- Tables can be added and removed after the initial design
- Objects can be renamed after connecting
To start using this feature, make sure you have the DirectQuery for PBI datasets and AS switched on in the Power BI Desktop Options dialog. Restart Desktop to apply any changes.
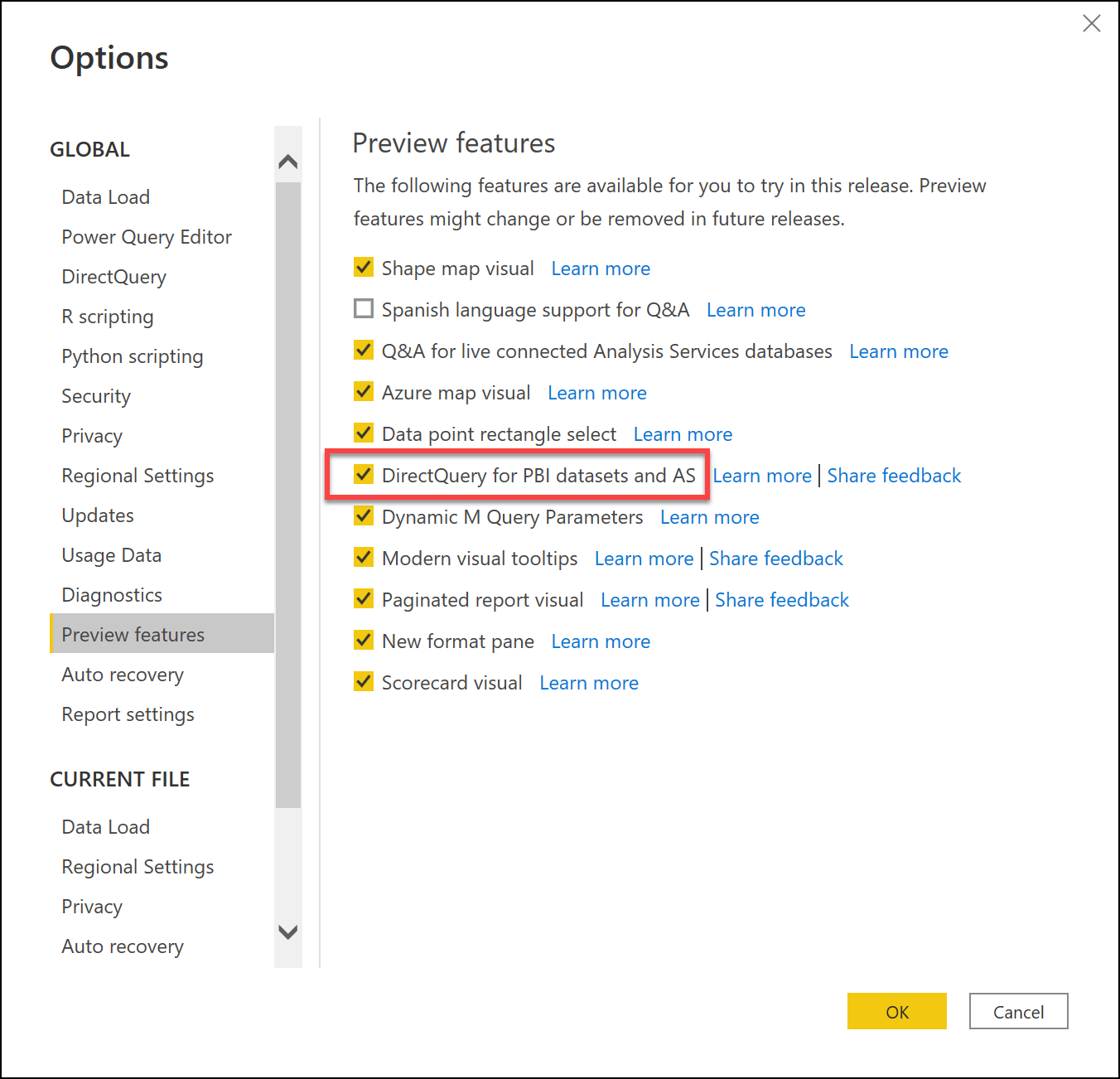
The Power BI tenant must have support for XMLA endpoints enabled. This is managed in the Admin Portal under Tenant settings > Integration settings.

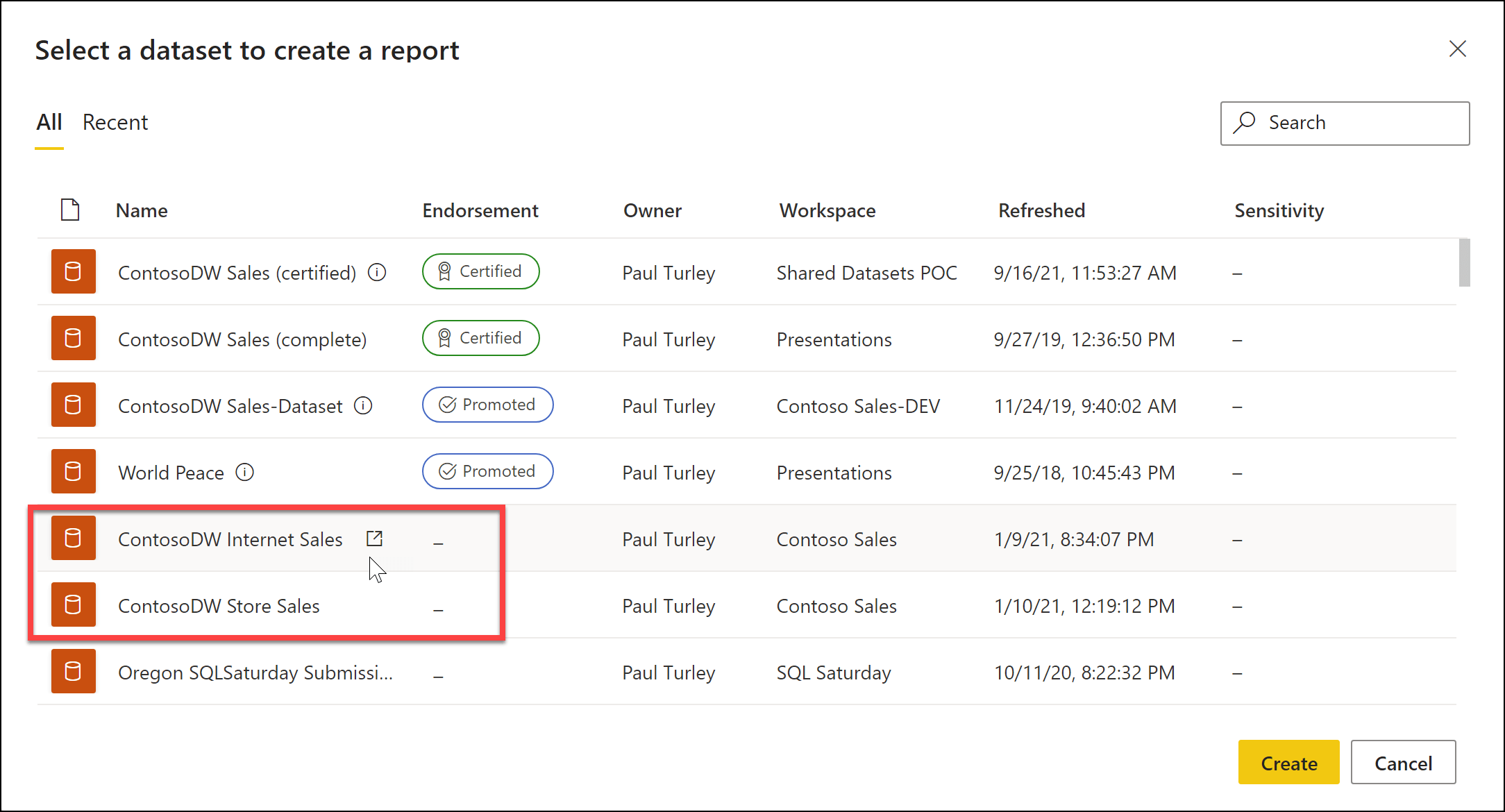
After all datasets that you intend to use in remote connections have been published and access is granted from the respective workspaces, open or create a new PBIX file in Power BI Desktop. Here are the two published datasets I’ll use in my new composite model:
Use Get Data and connect to a published Power BI dataset. After the live connection is made to the remote dataset, the message shown below will appear in the status bar. This is subtle and easy to miss.
Click the link titled Make changes to this model to update the data model and convert the connection to use DirectQuery for AS.

You will be prompted to confirm the change.
It is a good idea to make a backup of the PBIX before using a preview feature but there is little risk since this is a brand-new file for experimentation. However, keep this in mind for complex projects.
After making this change, using Get Data to connect additional datasets will result in DirectQuery connections. For each, you are prompted to select only the tables you want to include in the local data model.

If any objects in the remote model have the same name as those in the existing local model, those names will have a number appended to ensure uniqueness. This is true for tables and measures.
In the model diagram view, tables from the same remote model are displayed with a unique color in the heading. The default colors for the first two remote datasets are blue and purple, shown here. These colors are similar so watch carefully.
Just like a like a standard Import model, you can create relationships between any of the tables by dragging and dropping the key fields. Always double-check the relationship type and cardinality. Note that the relationship I just created between the Store and Geography 2 tables is incorrect (1:1 and bidirectional) which I will correct by editing the relationship, changing it to be one-to-many and a single-direction filter.

You cannot create a relationship between two tables (whether local or remote), if it conflicts with an existing relationship. This is bound to become a challenge in more complex composite models, but it is a reality in dimensional model design.
Objects can be added, removed and renamed
This is a huge improvement over the previous design experience. Tables can be removed one-by-one from the data model and additional tables from the same source can be added later by repeating the steps using the Get Data options. Tables, fields and measures can also be renamed. In short, I think we’re in a good place now, and this is a big improvement.
What About Performance?
There are many factors that can adversely affect the performance of reports, calculations and user interactions with a data model. Categorically, composite data models are bound to be less performant than a simple Import data model having all data residing within the same memory space. That’s just a fact. Experience has shown that DirectQuery has performance impacts just due to the nature of query mechanics, and interactions between different databases, and network latency. In many cases, performance will be a trade-off for the convenience of data model consolidation using DirectQuery and composite models in general. Optimization techniques like aggregations will help. Time will tell with this new capability. With this incredibly powerful new tool there will be many opportunities to implement poor design choices and to take Power BI to – and beyond – its limits.
There are several methods to tune and optimize models to run faster and perform well. I’m personally anxious to start using production-scale data with Gen2 composite models to test the water beyond small demo datasets. Please share your experience and I’ll continue to share mine.

Hi Paul, you mention that you’ve raised the issue of “all viewers of reports built on composite models require Build permissions on the remote model” with the product team. For us this is a big no-go to further implement composite models within our enterprise. Would you have any update from the product team on this issue for me?
Kind regards,
Fraukje
Front-end Teamlead of BI Team Data & Analytics
University of Applied Sciences Utrecht, The Netherlands
Hi Paul,
Thank you for the great article on Composite models which provides more insight in building complex data models.
As per my understanding the Preview feature available in desktop supports up to 3 levels of chaining and beyond which is not supported or do we still have an option to increase the level as this adds more number of datasets to be combined together as 1 single large dataset.
Could you also advise if we have any feature in Power BI available other than data modelling approach to access multiple datasets together.
Legacy SAP Business Objects XI 3.1 has a feature of merging different data models data together based on common dimension attributes.
Link: https://www.dagira.com/2010/06/19/what-does-extend-merged-dimensions-really-do/#more-292
Hi Paul,
Please advise for any inputs on the feature availability in Power BI rather than depending on data modelling approach.
Thanks for such useful post
https://marketreportsinsights.com/de/industry-forecast/power-transformers-market-2022-134723
Until now this is hardly anywhere used in the Power BI-field and why does it stick so long in preview? It is looking like one of this famous initiatives which dies off. We did a project and wanted to change to powerbi embedded and found it does not work on the embedded license …
In the scenario where you have one (or more) Power BI Datasets that use Import Data, and then you use DirectQuery to build a composite model for a report, are there still significant performance impacts (as when you direct query a source database), or are those mitigated by the source datasets also being in Power BI Service?
The greatest performance impact when using DirectQuery for most data sources, is the translation from the DAX query generated by interacting with visuals – to the native query language of the source (perhaps SQL). With DirectQuery for Power BI published datasets this latency is significantly reduced because the DAX query is is sent to the source dataset. In my experience with this so far, Power BI dataset-to-dataset DQ interactions are much faster than Power BI to SQL DQ interactions. There is some latency, though.
Hi Paul,
Thanks for the interesting article.
I have a dataset with a dimension table and another one with the fact table. I am joining them through a direct query composite dataset, but the relationship does not work well: The cardinality detection is sometimes incorrect (sometimes does not validate the one-side but there are really unique values) when I manage to make this work and check the data (filtering single values of the fact table) I get the error message saying it cannot show more than 1000000 rows (when I simply expect to see one row with the value of the dimension field connected to the fact table record.
I still can’t figure out if these are limitations of relations through direct query of datasets feature in preview, or something else is faulty in my setup.
Hello, Paul! Thanks for your articles!
Maybe you have a chance to make a assumption ( BigQuery datasource and Mixed model with Aggregations) – why at file opening – i receive such a DQ code (from performance analyzer), which takes some time to query the data source. It appears once , and can appear on one or another visual. Really something strange! Will be very grateful for your comment.
// Direct Query
let
table = Table.FromValue(Accuracy – table with DQ),
flat = Table.RemoveColumns(table, Table.ColumnsOfType(table, {type table, type record, type list})),
dqCaps = DirectQueryCapabilities.From(flat)
in
dqCaps
This is curious. I assume that this is some kind for metadata query, exectuted before fetching records, but I’m not familiar with the process. Aside from the community site, I would run this by Chris Webb on his blog. Reza Rad might also be a good resource, although I know he’s currently on a holiday trip.
Please share what you find.
Sorry if you mentioned it (I didn’t see it), but to me the biggest gap was the security and licensing requirements necessary to use this feature. Last time i checked (6 months ago), every Report Viewer user need to be a power bi pro license, and had to have at least contributor rights to the workspace the datasets all resided in. This is a non-starter in the enterprise environment-especially with PBI Premium licensing.
That being said, this unicorn would be a game change for our team.
Good points Jamie!
The phrase “have at least contributor rights to the workspace the datasets all resided in” is partially true.
The report viewers need to have Build permissions to the remote datasets.
If you’re contributor, member or admin to a workspace, you automatically have edit rights to all artifacts (including Datasets). So indirectly you have Build too.
Since give Build permission to everyone is a no-go for me, I don’t use it in production either.
Good news is that I’ve read in some tweet that this restriction (viewers needing Build) is one of the reasons why it still is in preview. So, I’m hopping to it do drop soon!
Thanks for the comment, Renato. I’ve raised this with the product team. Responses are slow due to the holidays but it seems to be a concern they are aware of.
Jamie, I ran your question past the product team and members of the MVP community. You are correct in that an author of a new composite model that connects to an existing dataset must have a pro license and contributor rights to publish their model to a workspace.
However, a report user should not need a pro license.