The December 2021 Power BI Desktop update introduced a long-awaited upgrade to the partitioning and Incremental Refresh feature set. The update introduces Hybrid Tables, a new Premium feature that combines the advantages of in-memory Import Mode storage with real-time DirectQuery data access; this is a big step forward for large model management and real-time analytic reporting.
Partitions allow us to break large tables in a data model into smaller, manageable storage units for a variety of reasons. Until recently, each table in the data model could be stored only in Import storage mode or as a DirectQuery table, which stored no data in the model. Generally, Import mode is fast and full-featured but large tables take up memory, while DirectQuery uses no memory for storage but is typically slower and limits many reporting features. Incremental Refresh can automatically break a table down so that only partitions containing new or changed records can be refreshed. There are two scenarios where combining Import and DirectQuery mode partitions might be optimal: 1. providing real-time access to recently inserted records, or: 2. proving access to infrequently accessed old records that take up a lot of storage space. This demonstration addresses the first scenario.
Hybrid tables, an extension to the Incremental Refresh feature set, can consist of both Import Mode and DirectQuery partitions, so that some data is cached in memory and some records are read directly from the data source as users interact with the data model. Setting up Incremental Refresh is the same as it was when introduced a few years ago, but the options have been enhanced.
Let’s take a look at the updated Incremental Refresh dialog for a fact table. I will demonstrate with three years of historic fact data so you can see the results. I’ve already setup the required query parameters and filter step needed to enable the feature, that I described in this post. Choosing the Incremental Refresh option from the ellipsis menu for the Online Sales table opens this dialog. There’s a lot going on in this window but pay attention to the following options that I have called-out in the graphic:
- Enable automatic partitioning by switching on “Incrementally refresh this table”
- Archive data starting 3 Years before refresh date
- Incrementally refresh data starting 12 Months before refresh date
- Enable Get the latest data in real time with DirectQuery

For simplicity, I have not set the Detect data changes option, which is something I typically would also do but we’re just keeping this demonstration focused on the topic of how partitions are created.
Note the graphic added to the bottom of the dialog window, which displays a graphical representation of the results. I will break this down into more detail using the following graphic. Let’s see the effect of these settings The graphic depicts the partitioning scheme for the Online Sales fact table in this data model. Bases on the settings in this dialog, the Power BI service will generate partitions using the RangeStart and RangeEnd query parameters to inject dates into the WHERE clause of each partition query. A few query examples are shown for demonstration purposes. The dark-colored boxes represent the Import Mode partitions that cache a copy of data in the model, and the light-colored box represents a DirectQuery partition that runs in real time when the model is used for reporting. Note that I have abbreviated things for illustration purposes, and there will actually be more monthly partitions than those represented here.
Referencing the earlier Incremental Refresh settings dialog, the Archive date starting option specifies three years, which generates three yearly partitions, each with a relative date range. The Incrementally refresh data starting option specifies 12 months, which generates 12 monthly partitions (only 3 are illustrated here). The example query shows a range of one month per partition query. Lastly, a DirectQuery partition uses a range of dates to include all records in the current month and possible future dates.

These partitions are created by the Power BI service the first time the dataset is processed, after the data model is deployed to a Premium Capacity or Premium Per User workspace.
Let’s take a look at the actual partitions. Using the XMLA endpoint, I can use the workspace URI address to connect to the service using SQL Server Management Studio and show the partitions for the Online Sales table. With 15 partitions, it takes longer initially, to process the dataset than it would if it were not partitioned. This is because the database engine only processes a few queries at a time. However, subsequent refresh cycles should be much faster since only a few partitions will need to be processed with additions and changes.
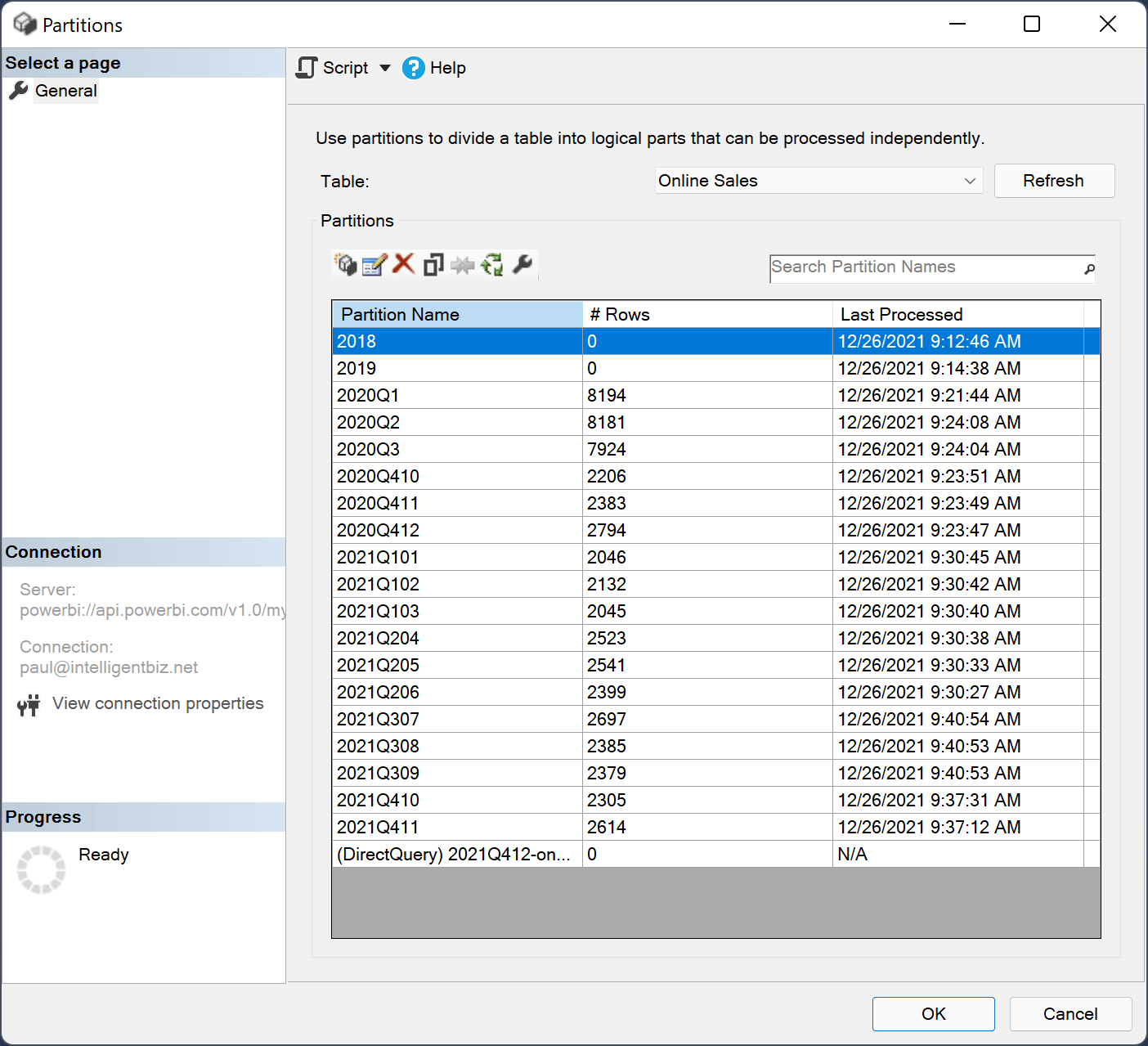
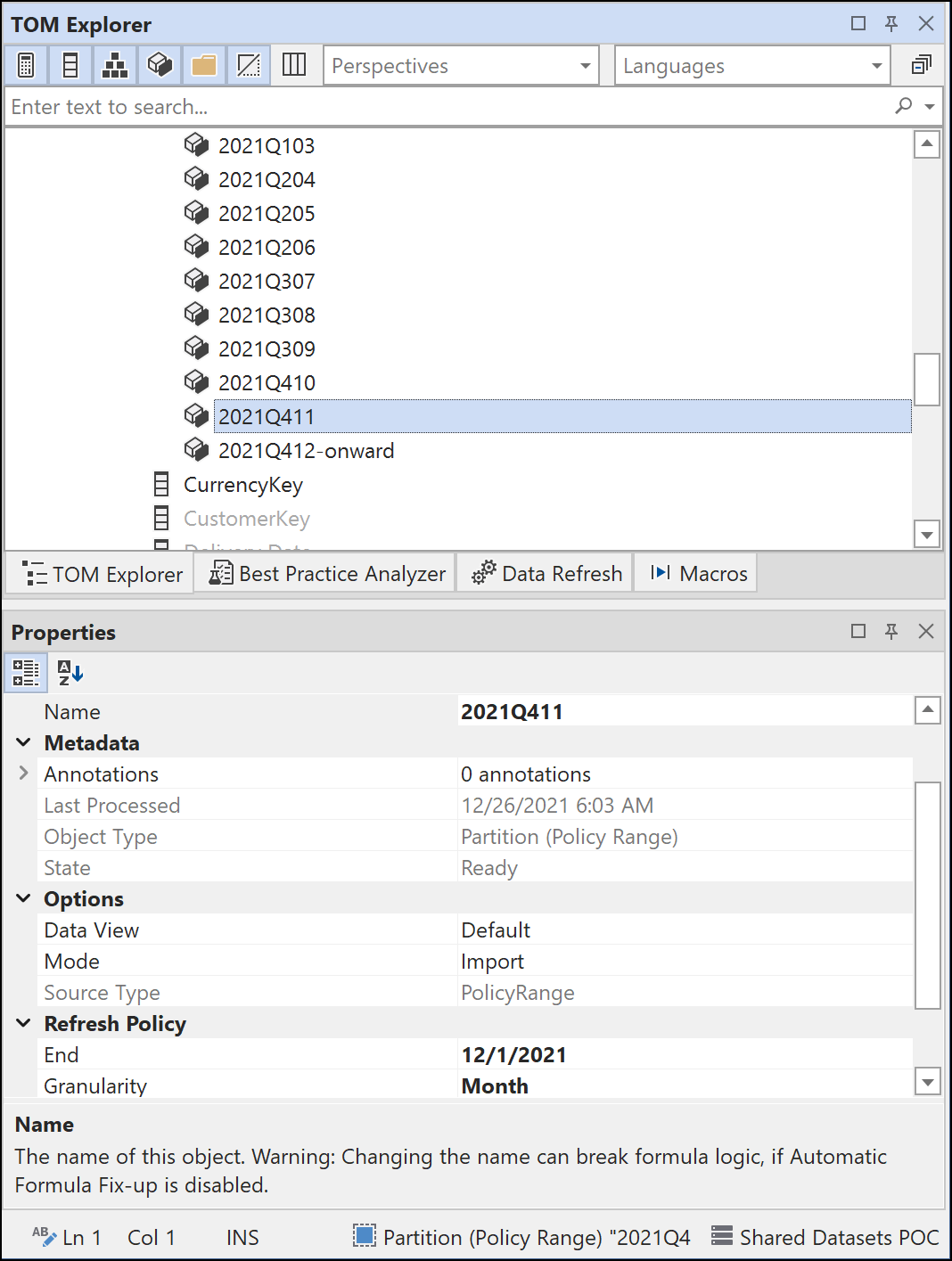
Connecting to the published dataset using Tabular Editor shows even more partition details. Here, you see the monthly partition for November 2021. The Start and End dates for this partition are 11/1/2021 and 12/1/2021 (US date format), respectively.
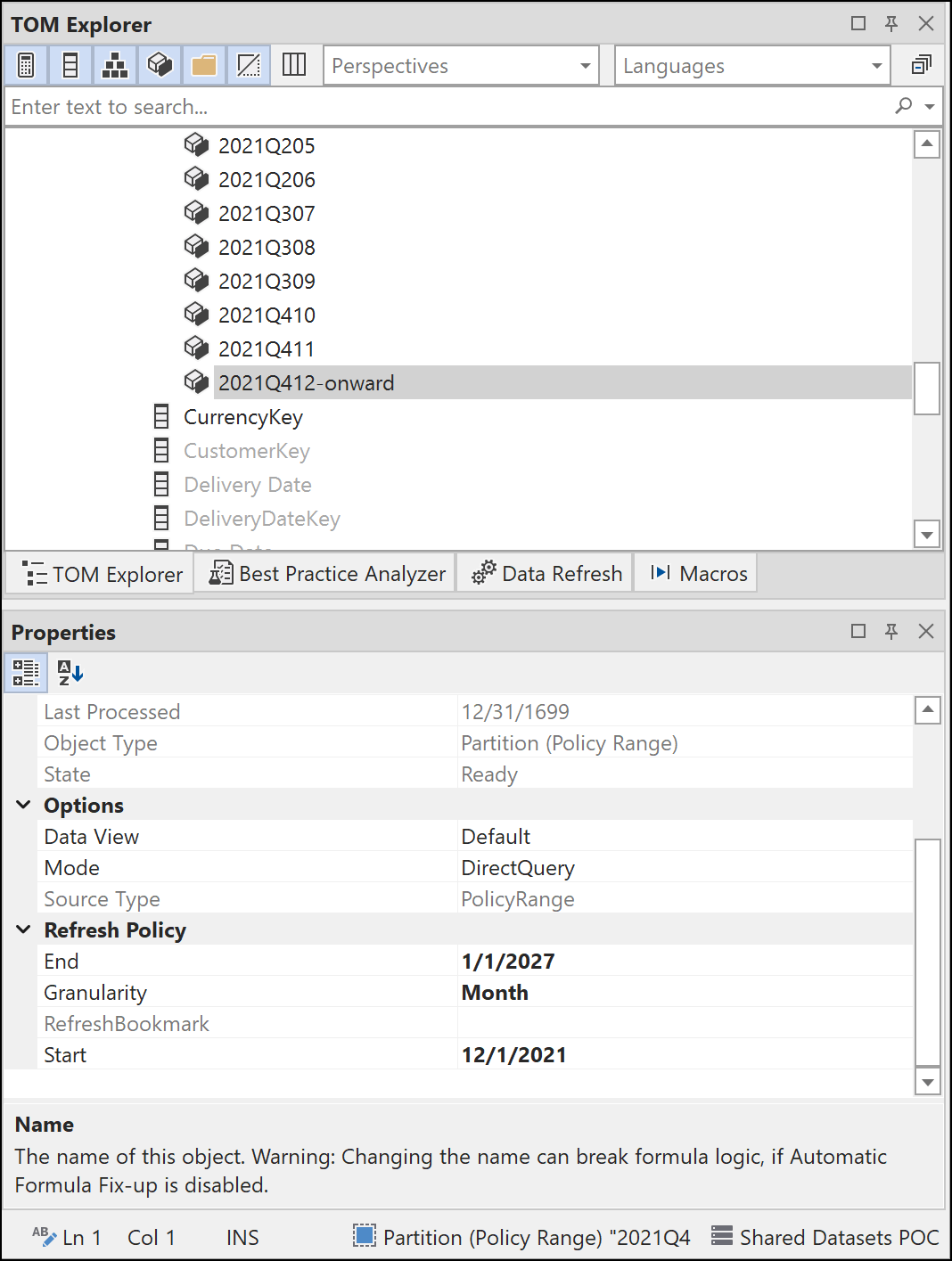
The last partition, which is in DirectQuery mode has a Start date of 12/1/2021 and an End date several years in the future. This range is a catch-all for records that could potentially have future dates.
- What are the performance implications of a hybrid table?
- How can you add an historic partition that uses DirectQuery mode?
I will address these questions in a later post. Please share your experience using the comments for this post.
The documentation on this feature is very brief right now, but here are some additional resources:
Hybrid tables | Microsoft Docs
Power BI Hybrid Tables with Synapse Analytics Serverless SQL Pools – Serverless SQL

Is it possible to partition a tabular model in VS/Tabular editor like this or does it have to be done in PowerBI ?
You might want to have a look here; https://docs.tabulareditor.com/te2/incremental-refresh.html