
Microsoft Fabric #MicrosoftFabric, the new Unified Analytics platform, was announced this morning, literally moments before the Build Conference. Satya Nadella is making the official announcement in the keynote address as I am writing this. Why is this big news and why is it important? In a few words, this is the most significant expansion to the Power BI and the analytics platform since the product was introduced. Satya said that Fabric is the most significant data platform innovation since SQL Server. We’ve had about 50 developers and architects from 3Cloud Solutions working with Fabric (aka “project Trident”) and the Microsoft product team to provide feedback for the past several months.
Every component of the Lakehouse data engineering architecture depicted in the following diagram can be added to a Power BI workspace. In the past, BI developers depended on data engineers, DBAs and developers to deploy ETL, data lake files, databases, pipelines and notebooks to populate a data warehouse. Fabric enables all of these components to be developed and managed in the Power BI platform as native assets.
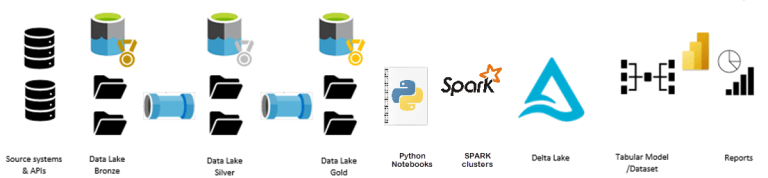
Familiar and mature technologies are part of this collection, which include SPARK clusters, Python notebooks, ADF pipelines; and data developers already know how to use them. The exhaustive breakdown of all these components is very plentiful and I’ve shared some of them below. Many important questions are addressed such as security, access, integration, version control and build management. Here’s a quick look at the new items that can be added in an enabled Power BI workspace:
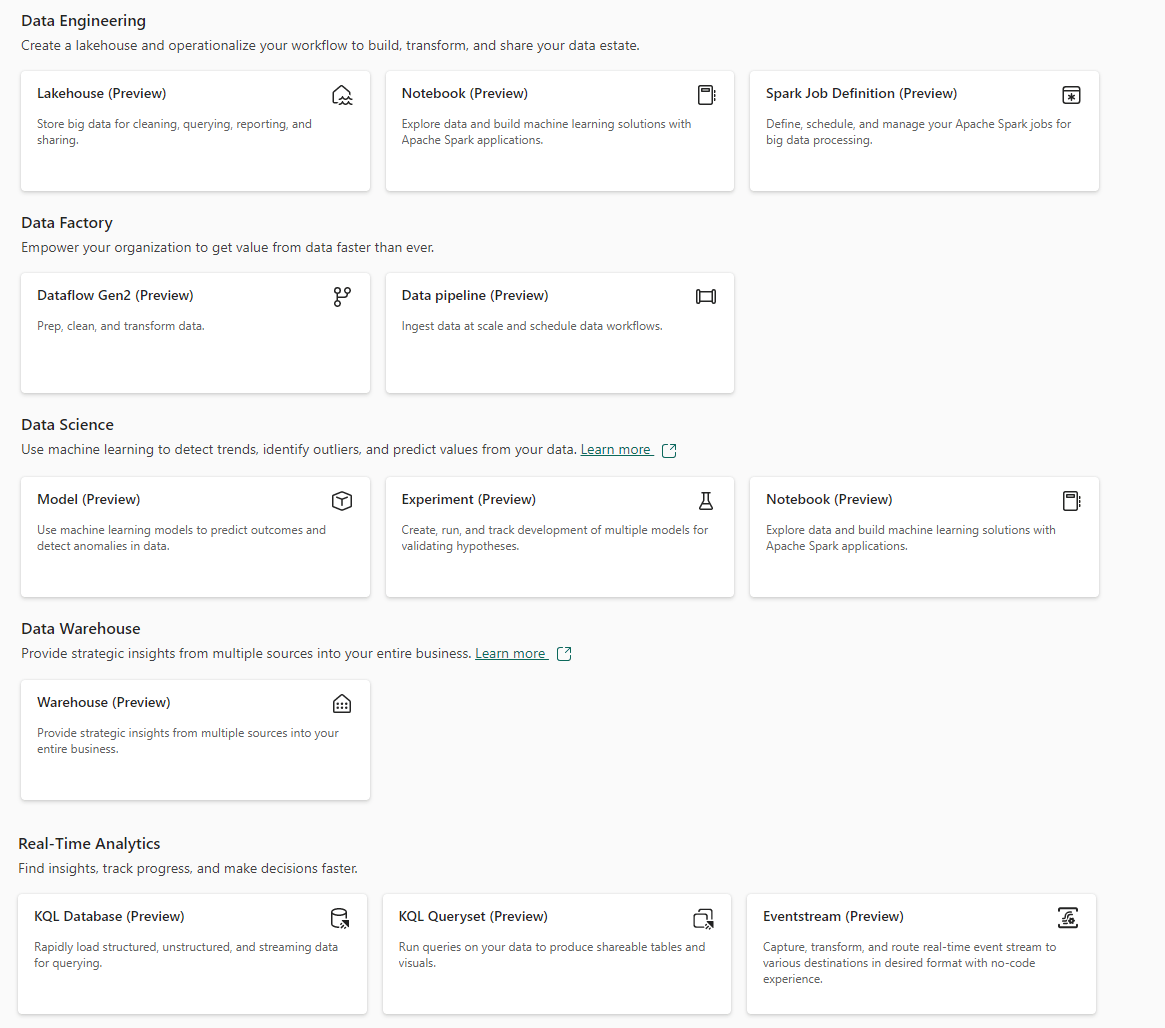
There is a firehose of information around this announcement, but here are a few of the most important things to know about how Fabric changes the Power BI paradigm:
OneLake – The simplified implementation of Azure Data Lake Gen2, is like OneDrive for Business. A lakehouse is a storage container for files in any format. Parquet files stored in a lakehouse folder are represented as a delta table with indexing, key enforcement, strong data types and referential integrity. Lakehouse data can be transformed using native pipelines and notebooks using Python and SQL.
Power BI DirectLake – When this feature matures, in the service tabular model storage will move to parquet file delta tables. DirectLake is DirectQuery over real-time connected delta tables that provide very fast live connectivity to real-time, high-volume storage.
Power BI Developer Mode – Power BI Desktop will now save data model and report projects to open, text-based object definition files in a local folder structure with native Git integration. All objects can be versioned, split, branched and merged to support version control and collaborative development. Workspaces integrate with Azure DevOps to support true CI/CD automated build pipelines.
Is Fabric ready for primetime?
No, it’s barely in public preview. We’ve been working with “Project Trident” for the past year, and it has been growing up rapidly but there are components that still need to mature before it reaches GA. We experienced a short service outage just two days ago, but they patched it and recovered quickly. I think that DirectLake will take some time to become bullet-proof. Developer Mode and Git integration are not ready yet. It has not been rushed to market but some of these components are new and need to finish incubating. The components we know how to use based on previous experience with Databricks, ADF and Synapse; have proven to be pretty solid based on our testing. I think it is time to start building POC projects using production-scale data workloads.
Microsoft Fabric Resources
From Microsoft, you can learn more about Microsoft Fabric at aka.ms/microsoft-fabric or aka.ms/fabric
•Signing up for the Microsoft Fabric free trial
•Visiting the Microsoft Fabric website
•Reading the more in-depth Fabric experience announcement blogs:
•Data Factory experience in Fabric blog
•Synapse Data Engineering experience in Fabric blog
•Synapse Data Science experience in Fabric blog
•Synapse Data Warehousing experience in Fabric blog
•Synapse Real-Time Analytics experience in Fabric blog
•Data Activator experience in Fabric blog
•Administration and governance in Fabric blog
•Microsoft 365 data integration in Fabric blog
•Dataverse and Microsoft Fabric integration blog
•Exploring the Fabric technical documentation
•Reading the free e-book on getting started with Fabric
•Watching the free Fabric webinar series
•Exploring Fabric through the Guided Tour
•Joining the Fabric community to post your questions, share your feedback, and learn from others

The introduction of Microsoft Fabric marks a significant shift in the Power BI landscape, offering a comprehensive platform for analytics with native integration of familiar tools like Azure Data Lake Gen2 and Git. While still in its early stages, Fabric shows promise for streamlining development processes and enhancing collaboration among data professionals.
Really microsoft fabric are change the enterprise bi game this technology is awesome and many advantages of this technology thanks for sharing this informative article keep share
AFAIK, Direct Lake is more like VertiPaq over the Delta files, but not DirectQuery.
nice summary, but where is the answer to the question in the title? 🙂